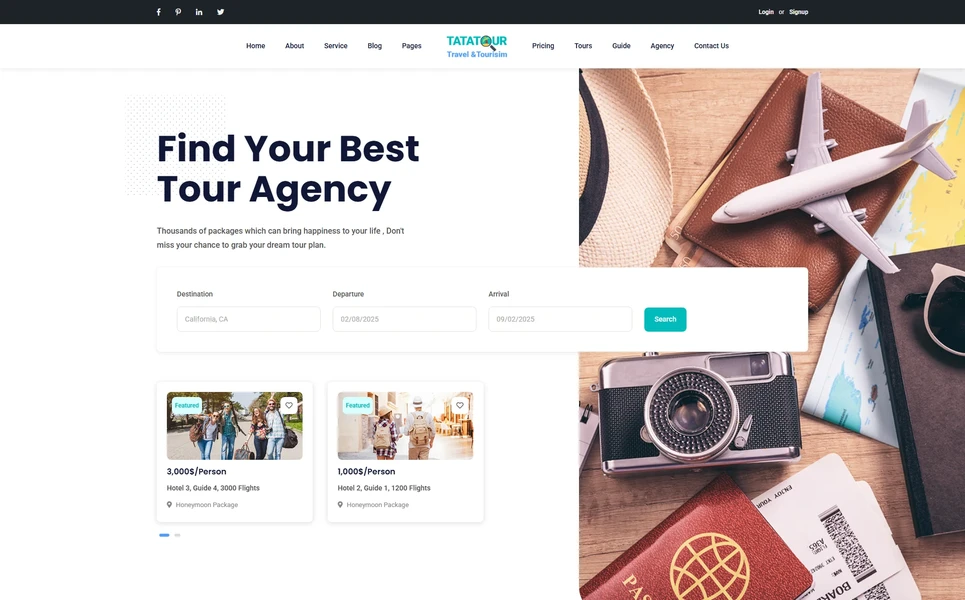
Every product page on MetropolitanHost publishes a number we call the AICE block — short for AI Cost Estimator — and the number is the projected cost to rebuild that template from scratch using the major coding-capable AI models. As of the May 2026 audit we are the first template marketplace to publish this transparency on every product page in our catalog, and we expect to remain the only one for the foreseeable future. This article is the long-form explanation of how the AICE number is computed, what the inputs are, what the assumptions are, where the model prices come from, and how a buyer should interpret the result. The goal is to make every step verifiable, so the buyer who wants to cross-check our math can do it directly against the vendor pricing pages.
The article uses Miranda — our Bootstrap 5 hotel template — as the worked example throughout, because Miranda’s AICE block has been running with verified prices since early 2026 and the numbers are stable enough to walk through end to end. Every figure quoted from Miranda below is read directly from the WordPress post-meta the AICE plugin writes after each sync. None of the numbers are illustrative.
What “AICE” stands for and why we settled on the name
AICE stands for AI Cost Estimator. We considered AI Compute Estimate and AI Build Cost in early drafts and rejected both. Compute Estimate sounded too narrow — the number includes input plus output token cost, not raw compute. Build Cost sounded too broad — a real build cost includes the buyer’s time, design iteration, and integration work, none of which the AICE number captures. AI Cost Estimator names the thing accurately: it is an estimator, computed from the source code, of what an AI model would cost in tokens to attempt a faithful rebuild. The buyer is doing the rest of the cost calculation themselves; AICE only takes the input the buyer cannot easily measure on their own.
Why publishing this number per template is unusual
Marketplaces typically do not publish AI rebuild estimates per template because the math is awkward to maintain at scale. Model prices change every few months as vendors compete on cost. Token-counting heuristics differ slightly across model families. Output-to-input ratios depend on the agentic-coding pattern the buyer is running. A marketplace that wants to ship a credible per-template AICE number has to maintain a pricing manifest, a token-counting analyzer, a per-template sync loop, and a published methodology that survives buyer scrutiny. The ROI on doing all of that is the buyer’s trust, which is harder to monetize than a one-line listing price. We do it because we think transparency is the right standard for the in-house tier of the marketplace, and we are the only studio in the in-house tier with enough catalog scale to justify the engineering investment.
The AICE pipeline at a glance
The pipeline has four stages. First, an analyzer walks the template’s source directory and counts characters across HTML, CSS, and JavaScript files using a format-aware extension list. Second, a token-estimation step converts character counts into output tokens at a fixed chars-per-token ratio. Third, a scenario layer multiplies output tokens by floor, typical, and ceiling input ratios to model three real-world build patterns. Fourth, a pricing layer multiplies token counts by the per-model rates from the pricing manifest and produces the dollar figures the product page displays. Every stage is deterministic — the same source produces the same numbers — and every stage logs its inputs to the post-meta layer so the buyer can audit the calculation per template.
Stage one — counting source characters by file type
The analyzer reads a JSON file called formats.json that maps each product format — html, php, angular, react, vue, wordpress — to a specific set of file extensions. The HTML5 base counts files ending in html, css, scss, less, sass, js, mjs, cjs, jsx, ts, tsx. The PHP build adds php, phtml. The Angular build adds ts, html-component templates, scss. Each format gets its own extension list because counting a Vue single-file component the way you count a flat HTML page would distort the cost. The analyzer skips third-party folders by default — node_modules, vendor, .git, dist, build, .next, .cache, bower_components, libraries — and skips files that match library signatures or carry license headers in the first kilobyte. This produces the first-party character count, which is the number the buyer’s developer or the AI agent would actually have to author.
The Miranda numbers — character counts
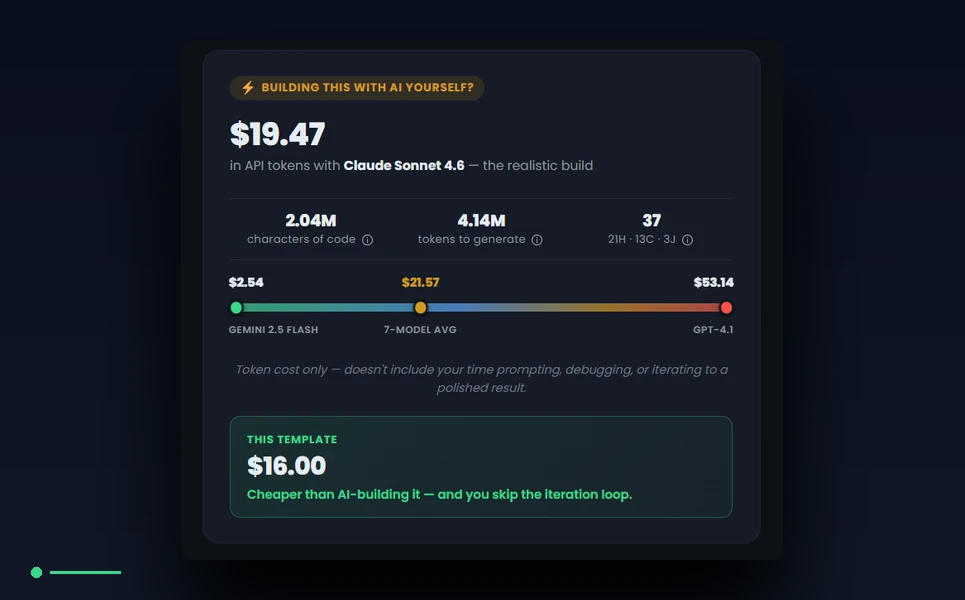
Miranda’s HTML5 base, scanned on the latest sync, counts to 2,279,842 first-party characters across 19 HTML files, 74 CSS files, and 22 JavaScript files. The third-party exclusion picks up an additional 811,697 characters across vendor and library files that the analyzer does not count toward the rebuild estimate. The framework detection labels Miranda as html-with-jquery, which determines which scenario assumptions apply. Every one of those numbers is recomputed on every plugin sync and written to the WordPress post-meta layer, where the product page reads them directly. The buyer who wants to verify the count can run the same analyzer against the source release and reproduce the numbers exactly.
Stage two — converting characters to output tokens
The estimation step divides the first-party character count by 3.5 to produce an output-token count. The ratio comes from the OpenAI tokenizer documentation and matches reasonably across Claude, Gemini and Cursor for typical code workloads — the tokenizers differ slightly per family, but 3.5 chars per token is a defensible average across the major model families and stays accurate within roughly five percent for code-heavy text. We document the ratio openly in the methodology so a buyer who prefers a different number can adjust it themselves and recompute. Miranda’s first-party characters at 2,279,842 divided by 3.5 produces roughly 651,383 output tokens.
Stage three — modeling the build with three scenarios
The scenario layer models three real-world agentic-build patterns by multiplying output tokens by an input ratio. The floor scenario assumes a single-shot build — one prompt, one response, no iteration — at a one-to-one input-to-output ratio. The typical scenario assumes a light agentic build, like Claude Code with /clear discipline, at a six-to-one input-to-output ratio. The ceiling scenario assumes heavy agentic patterns — Cursor-style file re-reads, no caching, retries — at a twelve-to-one input-to-output ratio. The three scenarios bracket the range of what a buyer is plausibly going to spend in tokens. We publish all three on every product page so the buyer can pick the one that matches their actual workflow.
The Miranda numbers — token totals across scenarios
Miranda’s typical-scenario token total is published as 4,604,688 input plus 651,383 output, for roughly 5.25 million tokens per faithful agentic rebuild. The floor scenario lands at roughly 1.3 million tokens. The ceiling scenario lands at roughly 8.5 million tokens. The buyer who runs a Claude Code session with disciplined clearing should expect the typical number. The buyer who runs a Cursor agent on a fresh context with frequent retries should expect the ceiling. The buyer who attempts a one-shot build will mostly fail to land a faithful rebuild on the floor budget, but the floor is published as the lower bound for completeness.
Stage four — applying per-model prices
The pricing manifest is a JSON file that lists every model the AICE block reports against, with per-million-token input and output prices, the vendor name, the model tier, and the URL of the vendor’s official pricing page that produced each number. Every entry carries a verification flag and a date — verified_2026_05_02 means the rate was pulled directly from the vendor’s pricing page on that date. The manifest is hand-edited rather than scraped, because the vendor pricing pages change layout often enough that a scraper would break silently. The hand-edit is a deliberate operational choice to keep the numbers trustworthy. We expose the manifest version and the audit date on every product page alongside the number, so the buyer can see how fresh the data is.
The pricing manifest — what we publish
The May 2026 manifest publishes verified rates for Claude Opus 4.7 at 5.00 dollars per million input tokens and 25.00 dollars per million output tokens — the rate from Anthropic’s official pricing page. Claude Sonnet 4.6 is 3.00 dollars input and 15.00 dollars output, same source. Claude Haiku 4.5 is 1.00 dollar input and 5.00 dollars output, same source. Gemini 2.5 Pro is 1.25 dollars input and 10.00 dollars output from Google’s pricing page, with a >200k input tier at 2.50 dollars and 15.00 dollars. Gemini 2.5 Flash is 0.30 dollars input and 2.50 dollars output, same source. GPT-5 and GPT-4.1 rates are pulled from OpenAI’s pricing page at 5/15 and 10/30 respectively, with the manifest flagging both as unverified for the May 2026 audit because the vendor’s pricing page returned a 403 to the audit fetch. The manifest is open about that gap.
The Miranda numbers — dollar figures by model
Applied to Miranda’s typical-scenario token totals, the manifest produces these dollar figures. Claude Sonnet 4.6 lands at 21.69 dollars on a typical agentic build. Claude Opus 4.7 lands at 36.15 dollars. Gemini 2.5 Flash lands at 2.83 dollars and is the cheapest model in the manifest. GPT-4.1 lands at 59.17 dollars and is the most expensive. The average across the major model families on the typical scenario is 24.02 dollars, which is the headline number Miranda publishes on its product page. The buyer who wants the per-model breakdown can hover the AICE block on the product page; every figure is exposed.
The platform layer — Cursor, Claude Code, Lovable, Replit, Bolt, v0
Most non-developer buyers do not pay vendors directly per token. They pay a platform — Cursor Pro at 20 dollars a month, Claude Code at 20 dollars a month, Lovable Pro at 25 dollars a month, Replit Core at 20 dollars a month, Bolt.new Pro at 25 dollars a month, v0 Team at 30 dollars a month. The AICE block computes a platform-amortized number per template by mapping the template’s typical token total against each platform’s monthly token allowance and reporting the cost as a fraction of the monthly seat. Cursor Pro’s roughly 30 million monthly token allowance covers Miranda comfortably inside one month. Lovable Pro’s roughly 6 million covers Miranda barely. The buyer can see how the template fits inside their existing platform subscription before deciding whether the template is worth the marginal seat cost.
Reference URLs the buyer can verify against
Every model and platform price in the AICE manifest links back to its source. The buyer who wants to verify any of the numbers can open Anthropic’s pricing, Google’s pricing, OpenAI’s pricing, Cursor’s pricing, Claude’s pricing, Lovable’s pricing, Replit’s pricing, Bolt’s pricing, or v0’s pricing and confirm the rate the manifest uses. Where a vendor’s page returned a 403 or required authentication during the audit, the manifest flags the rate as unverified rather than printing it as if it were verified — that flag is visible per model in the product page tooltip.
The framework calibration
The framework label on each template — html-with-jquery, html-static, react, react-nextjs, vue, vue-nuxt, svelte, wordpress-theme — does not change which characters get counted, but it does change how the buyer should interpret the numbers. A WordPress theme rebuild has different agentic dynamics than a React Next.js rebuild, even at the same character count, because the WordPress theme has to satisfy the WordPress hook system and the React app has to satisfy the framework’s data-fetching contract. The framework label tells the buyer which body of expectations applies. Miranda’s label is html-with-jquery, which means the rebuild’s complexity sits in the rendering and animation layer rather than in framework integration.
What the AICE number does not capture
The AICE number is intentionally narrow. It captures the model’s token cost for one faithful agentic rebuild attempt. It does not capture the buyer’s time, the iteration overhead when the first attempt is wrong, the integration with the buyer’s existing design system, the customization layer the marketplace template ships with, the accessibility audit, the performance budget, the documented support cadence, or any of the operational tax that comes from owning the rebuild’s lifecycle. The buyer who compares the template’s listing price against the AICE number directly is comparing two things that are not the same. The honest comparison is the AICE number plus the buyer’s time at the buyer’s billable rate plus the cost of the things AICE explicitly excludes. We document this caveat openly on the product page so the buyer can frame the comparison correctly.
How the AICE block is wired into the product page
The implementation is a WordPress plugin called mh-aice that owns the analyzer, the pricing class, the manifest, and the post-meta writer. The theme reads the meta only — it never re-runs the analyzer at request time. The plugin syncs the manifest into post-meta on Action Scheduler queue runs at a rate of one product per ten seconds, so a full catalog sync of a few hundred products spreads across roughly half an hour without overwhelming the server. The buyer sees the published numbers without any runtime cost, because every figure on the product page is a direct meta read. The plugin’s hard guards — 5,000 files maximum, 100 million characters maximum, 5 megabytes per file — protect the server from runaway scans on accidentally large source trees.
How often the manifest is audited
The pricing manifest carries an explicit audit date and a per-model verification flag. We audit every quarter at minimum, and immediately whenever a vendor publishes a major price change. The audit is a manual fetch of each vendor’s pricing page, a comparison of the manifest’s numbers against the page, and a hand-edit of any discrepancies. We have considered automating the fetch through a scraper or an API watcher, but every vendor’s pricing page changes layout often enough that the scraper would break silently and produce stale numbers worse than no numbers at all. The manual audit is the right operational choice. The audit date is exposed on every product page so the buyer can see how recent the data is.
Why we expose the manifest version on the product page
The manifest version stamp on each product page is the single biggest commitment to transparency we make. It tells the buyer exactly which manifest produced the numbers they are looking at, so a buyer who returns to the page in two months and sees a different number can identify which audit produced the change. Manifests carry an ISO date and a brief change log, both visible per product page. A marketplace that publishes a Lighthouse score without telling the buyer when the score was captured is publishing a number with no audit trail. We treat the AICE number the same way. Audit-stamping every figure is cheap. The buyer’s trust is not.
Why we are the first marketplace to do this
MetropolitanHost is the first template marketplace to publish per-template AI rebuild costs as a standard product-page feature, computed from the source code, against verified vendor pricing, with the audit trail open. The reasons no one else has done it before are structural. Global marketplaces with third-party authors cannot enforce a uniform manifest across their catalog because each author would need to opt in. Offshore marketplaces lack the engineering capacity to maintain the manifest at the cadence the model vendors ship pricing changes. Local studios do not have a catalog at all to publish across. In-house marketplaces — the smallest of the four marketplace archetypes — are structurally the only kind of marketplace that can ship a consistent manifest across an entire catalog, because the same team owns every product and the same plugin computes every number. We are happy for the rest of the market to follow. We expect them to take a while.
How buyers should use the numbers
The right way to use the AICE block is as one input into a four-dimension cost calculation — fully laid out in our website cost calculator guide, not as a price comparison on its own. The buyer should look at the typical-scenario number for the model the buyer would actually use as an alternative — Claude Sonnet 4.6 if the buyer runs Claude Code, GPT-4.1 if the buyer runs OpenAI directly, Gemini 2.5 Flash if the buyer is shopping on cost — multiply by an honest estimate of how many iterations the buyer would need, add the buyer’s own time at the buyer’s billable rate, compare the total against the template’s listing price plus its customization labor and maintenance burden, and decide accordingly. Most buyers who run the math arrive at a number that favors the template. Some buyers arrive at a number that favors the rebuild, which means the template is wrong for the project — also a useful outcome.
The transparency cost we accept
Publishing the AICE number per template costs us conversions on the cheapest SKUs in our catalog. A buyer who looks at a forty-nine-dollar HTML5 base and a 2.83-dollar AI rebuild number and stops there is going to skip the template. We accept that cost because the buyer who stops there is rarely the buyer who would have been a good fit for our work in the first place. The buyer who runs the rest of the math — customization layer, maintenance burden, accessibility audit, framework parity, direct support, AI rebuild — almost always arrives at a value comparison the template wins. Publishing the AICE number filters our buyer pool toward the buyer who runs the math, which is the buyer we serve well.
What the AICE block looks like across the rest of our catalog
Every template in our catalog publishes its own AICE block with the same methodology. (For the broader category context: the premium HTML5 baseline is in our HTML5 buyer’s guide, the Bootstrap 5 marketplace archetypes are in our Bootstrap 5 guide, the small-business angle is in our small business templates guide, and the performance methodology is in our PageSpeed templates guide.) Restaurant templates land in the same neighborhood as Miranda — high single-digit dollars on the cheapest model, mid-twenty dollars on the typical scenario across the majors, mid-fifty dollars on the ceiling. Cycling and legal templates land slightly cheaper because their codebases are smaller. Cannabis templates land slightly higher because the regulatory disclosure layer adds character count. Hotel and hospitality templates land highest among our standard catalog because they ship the most blocks. The AICE numbers are visible on every product page and the math is the same per template, so a buyer comparing two templates from our catalog can compare like for like.
Final word — transparency is the operational choice we ship
The AICE block is the most visible piece of the operational discipline we run across the catalog, but it is not the only one. Every template publishes its Lighthouse score against realistic content, its WCAG 2.2 AA audit log, its schema graph, its update cadence, its support policy, and now its AI rebuild cost across the major model families. The buyer who treats the listing as a black box ends up paying for the lack of transparency in every other dimension. The buyer who treats the listing as a verified specification ends up making decisions the math actually supports. We built the AICE block to make at least one of those dimensions verifiable per template, against the vendor pricing pages the buyer can audit themselves. The rest of the market is welcome to copy the methodology — the manifest schema, the analyzer logic, the audit cadence — at any time.